Mandelbrot Polynomials and Matrices
Contents
Mandelbrot Polynomials and Matrices#
A note to the student/reader#
This unit uses some ideas of the late Benoit Mandelbrot and some known facts about the so-called Mandelbrot Set, together with some of our own ideas, to help you to learn the following:
A bit more Python programming, including more practice with the use of numerical libraries from NumPy, iteration and recursion; some new things, such as loop invariants, automatic differentiation, symbolic computation, and a bit more about graphics.
A bit more about polynomials: the cubic formula (we won’t need the quartic formula, and even our use of the cubic formula is a bit contrived; but we think it’s fun), the cost of numerical solution of polynomials (we will point you to the current numerical champion polynomial solver, MPSolve), and the rather necessary-to-know notions of numerical stability and conditioning. Most of these topics are not taught as thoroughly as they should be, in one’s first numerical analysis course; so this material here should strengthen the results when you do encounter them.
The surprising use of eigenvalues to find roots of polynomials. The first treatment of eigenvalues (typically in a Linear Algebra course, even though the problem is not, strictly speaking, linear) usually runs the other way around, and defines the eigenvalues of a matrix in terms of the characteristic polynomial of the matrix. Indeed, we will teach you a concept not in the textbooks: namely, the concept of a minimal height companion matrix and we will show you one such for the Mandelbrot polynomials.
A bit more about dynamical systems, especially about iteration and composition.
An excellent approximate formula for the largest magnitude root of the Mandelbrot polynomial.
An honest-to-goodness analytic solution to the Mandelbrot iteration (this is a very new result, published only in 2021), valid for all \(c\) outside the Mandelbrot set.
That we don’t know everything about Mandelbrot polynomials and matrices, and that you might be able to answer some open questions.
A note to the Instructor#
The students tend to really like this unit. Mandelbrot wrote so well that it is quite possible to ask students to read his papers (especially his math education papers). Read them yourself, if you haven’t already.
We have put some of our own research into this unit. We believe that the results we have included are accessible (and of course we believe that they are interesting). There are some open problems here that we believe some students (or you!) may be able to close for us. At the time of writing, the most itching one is whether or not the Mandelbrot polynomials are unimodal. This seems like it ought to be easy, but we couldn’t do it.
The notion of iteration (discrete dynamical system) is not, apparently, of interest to every mathematician. But it is an extremely powerful idea for computation, and there are many open mathematical problems associated with it. And it is natural to introduce in a computational context.
Rounding errors don’t play a terribly large role in this unit, although they do push us to eigenvalue methods and away from polynomials that have large coefficients. This may be problematic for some students to grasp.
The Mandelbrot Set and Mandelbrot Polynomials#
The Wikipedia article on the Mandelbrot Set is pretty comprehensive, and readable. We’ll sum up the definition here, and try to flesh it out a bit. The definition is based on the following, apparently very simple, function:
This is apparently only a simple quadratic in \(z\), and depends linearly on the constant \(c\). We now consider what happens when we repeatedly apply this function, starting at 0 (an apparently simple point). That is, put
and then define \(z_k\) for \(k=1\), \(k=2\), \(k=3\), and so on in turn by the iterative formula (or recursive formula, or dynamical formula)
This gives us \(z_1 = z_0^2 + c = 0^2 + c = c\), and then subsequently \(z_2 = z_1^2 + c = c^2 + c\), and then \(z_3 = (c^2+c)^2 + c = c^4 + 2c^3 + c^2 + c\), and so on.
Pass the parcel, again
In this unit one could play “Pass the Parcel” again in class, with the initiator choosing the the value of \(c\) and starting with \(z_0 = 0\) so \(z_1 = c\). Passing each successive \(z_k\) on to the next person to compute \(z_{k+1}\) makes the connection with the activity from Continued Fractions. Indeed, that game could be played with Newton iteration or Halley iteration for rootfinding, and for the iterations used in the Fractals unit. It’s a bit harder to find a “pass the parcel” game for Bohemian matrices but it could be done, if you wanted. In the next unit, on the Chaos Game Representation, there is a better game to play, but it is obviously related to this one.
Several important things are going on here: this looks simple, and in one sense it is, but we will see some surprising things from this. This is an example of a nonlinear dynamical system (perhaps the “most famous” example of a nonlinear dynamical system). We are repeatedly composing the function \(f(z) = z^2+c\) with itself: \(z_2 = f(c)\) and \(z_3 = f(f(c))\) and \(z_4 = f(f(f(c))\). Sometimes repeated composition is written with a power in brackets: \(f^{(n)}(c)\) means \(f(f(f(\cdots(f(c))\cdots)))\) where there are \(n\) copies of \(f\) used; this is where the pernicious notation \(f^{(-1)}(c)\) comes from, by the way. We will try to avoid this confusing notation. Several things can be deduced about repeated composition. For instance, the result of composing two polynomials together is another polynomial. If \(f(c)\) is of degree \(m\) and \(g(c)\) is of degree \(n\) then \(f(g(c))\) is of degree \(mn\), and so is \(g(f(c))\). If we were working with non-polynomials then we would also have to worry about matching up the domains and ranges, but polynomials are great because they always give a finite result output for any finite value input, and so composition always works.
We have written \(z_3\) out above as an explicit degree \(4\) polynomial (in the variable \(c\)), but if we actually want to compute a numerical value of \(z_3\) given a numerical value for \(c\) (say, \(c=-1.2\)) then it turns out to be better in several ways to just use the iterative formula itself and not the explicit polynomial. This is true even though we could write that explicit polynomial somewhat more efficiently in what is known as Horner form: \(z_3 = c\cdot(1 + c\cdot(1 + c\cdot(2 + c)))\), which can be evaluated using only three floating-point multiplications and three floating-point additions. Using the iterative formula directly, though, there is no work to compute \(z_0\), there is no floating-point work to compute \(z_1 = c\), there is one multiplication and one addition to compute \(z_2\), and one more multiplication and one more addition to compute \(z_3\), showing that \(z_3\) can be computed in only two “flops” instead of three. Note: one “flop” is defined to be one floating-point multiplication (or division) together with one floating-point addition (or subtraction). It’s not a fine-tuned measure; it was meant for use in older analyses of the cost of computation. On modern architectures, the notion is not really all that helpful; but you can see here that no matter what, the cost is less if we use the iteration directly. This advantage only increases as the iteration proceeds: to compute \(z_4\) you only need one more “flop,” i.e. \(3\) flops, whereas from its polynomial form you need \(2^3 = 8\) flops (even ignoring the work that has to be done simply to write the polynomial out). For \(z_{30}(c)\) the iteration takes only 29 flops; but the explicit polynomial is degree \(2^{29}\) and would take \(2^{29}\) flops to evaluate (actually, it’s worse: we would have to use multiple precision to deal with the big integer coefficients). Thus, somehow, the iteration has compressed a very high degree polynomial into a very efficient box.
Mandelbrot Activity 1
Read the Wikipedia entry on the Mandelbrot set, and the entry on Mandelbrot. Mandelbrot’s educational books and papers are amazing, and amazingly clearly written. If you don’t come back from this activity, well, at least you left going in a good direction. [Our thoughts]
Back to Mandelbrot iteration with a symbolic c#
Another important thing to notice in the above is that by leaving \(c\) symbolic, we have turned Mandelbrot’s iteration formula (or recursion formula) into some kind of generator for certain polynomials. These are called (naturally enough) Mandelbrot polynomials. We list the first few here, or at least their coefficients.
import numpy as np
from numpy.polynomial import Polynomial as Poly
N = 8
z0 = Poly([0])
print(z0)
c = Poly([0,1]) # We can do "symbolic polynomial arithmetic" just with these coefficient vectors in Python
z1 = z0*z0 + c
print(z1)
z2 = z1*z1 + c
print(z2)
z3 = z2*z2 + c
print(z3)
z4 = z3*z3 + c
print(z4)
z5 = z4*z4 + c
print(z5)
0.0
0.0 + 1.0·x¹
0.0 + 1.0·x¹ + 1.0·x²
0.0 + 1.0·x¹ + 1.0·x² + 2.0·x³ + 1.0·x⁴
0.0 + 1.0·x¹ + 1.0·x² + 2.0·x³ + 5.0·x⁴ + 6.0·x⁵ + 6.0·x⁶ + 4.0·x⁷ +
1.0·x⁸
0.0 + 1.0·x¹ + 1.0·x² + 2.0·x³ + 5.0·x⁴ + 14.0·x⁵ + 26.0·x⁶ + 44.0·x⁷ +
69.0·x⁸ + 94.0·x⁹ + 114.0·x¹⁰ + 116.0·x¹¹ + 94.0·x¹² + 60.0·x¹³ +
28.0·x¹⁴ + 8.0·x¹⁵ + 1.0·x¹⁶
Translating that Python notation for polynomials back into something standard, we have
The Mandelbrot set is defined to be the set of \(c\) for which this iteration remains bounded for all \(n\): that is, everything except those values of \(c\) for which \(|z_n| \to \infty\). That’s a weird sort of definition, and you have to first reassure yourself that there really are values of \(c\) for which the \(z_n\) do not remain bounded. Indeed, almost the first thing you would try was \(c=1\): then \(z_0 = 0\), \(z_1 = 1\), \(z_2 = 2\), \(z_3 = 5\), \(z_4 = 26\), and so on; each succeeding number is one more than the square of the previous, and this goes to infinity rapidly, in some sense.
Some Activities with Mandelbrot polynomials with a more mathematical flavour#
Mandelbrot Activity 2
Prove by induction that the degree of the \(n\)th Mandelbrot polynomial is \(2^{n-1}\), and that the leading coefficient is \(1\). [Our proof]
Mandelbrot Activity 3
Prove that \(c=-2\) and \(c=0\) are both in the Mandelbrot set. Show that all zeros of Mandelbrot polynomials give periodic orbits under the Mandelbrot iteration and are thus in the Mandelbrot set. [Our proofs]
Mandelbrot Activity 4
Is \(i = \sqrt{-1}\) in the Mandelbrot set? [Yes]
Mandelbrot Activity 5
Prove that the Mandelbrot polynomials are unimodal. At the time we write this, this question is open: solve it, and you could publish a paper with your proof (Maple Transactions would be a good place). The word “unimodal” just means that the size of the coefficients increases to a peak, and then decays again. As in \(z_4\), the peak might be attained by two coefficients, not just one. Seriously, we don’t know how to prove this. We think it’s true, though. [We’ve got nothing.]
Mandelbrot Activity 6
Solve \(z_3 = 0\) by hand, as follows. First, divide out the visible root, \(c=0\), to get the cubic equation \(0 = 1 + c + 2c^2 + c^3\). Then put \(c = \xi - 2/3\) so \(c^3 = (\xi -2/3)^3 = \xi^3 - 2\xi^2 + 4\xi/9 - 8/27\) which will transform the equation into a cubic in \(\xi\) of the form \(0 = q + p\xi + \xi^3\). Then put \(\xi = u + v\) (introducing two new variables seems like the opposite of progress, but trust us, it will help). This transforms the equation to \((u+v)^3 + p(u+v) + q = 0\), or \(u^3 + 3uv(u+v) + p(u+v) + q = 0\). Show that if you can find \(u\) and \(v\) that simultaneously solve \(3uv + p = 0\) and \(u^3 + v^3 + q = 0\) then you can solve the original equation. Do so. Your formula at the end should give you three, and only three, roots. Write out your answer explicitly, and compare it with (say) the answer from Wolfram Alpha. [Our derivation]
Programming Mandelbrot polynomial iterations#
Let us write a short program to evaluate Mandelbrot polynomials of arbitrary order. This code shows several features: how to define a procedure (function); how to set a type for a parameter (more of a hint than a requirement, sadly); the use of keyword arguments; and the use of comments.
# This short program will evaluate Mandelbrot polynomials at a given point,
# or else it will compute the coefficient vector of a Mandelbrot polynomial.
# Which it will do depends on the type of the argument "c."
def Mandelbrot(n: int, c):
z = 0*c # try to inherit the type of c
for i in range(n):
z = z*z + c
return(z)
That code tries to force the variable z to have the same data type as c does, by multiplying 0 by c and storing that type of 0 in the variable z. It’s probably not necessary, because the very first time the loop is executed z gets replaced by something involving c. But, in the case n==0 that loop won’t execute at all, and the value of z being returned will be 0. Let’s see if that works.
z = Mandelbrot(0, 1.2)
print(z)
0.0
z = Mandelbrot(0, Poly([0,1]))
print(z)
0.0
Ok, so it doesn’t. This is a bit disappointing. However, it’s pretty harmless in this case, so we just leave the code as it is. To be fair, deciding automatically what type of zero one should return is fairly difficult. Is \(0\) different from 0.0 + 0.0j? How about a zero polynomial of grade 3, like \(0 + 0x + 0x^2 + 0x^3\)? Or a five hundred by five hundred matrix of zeros? The data type of computational objects really matters, in many cases. But for us, here, let’s just move on.
Now let’s experiment with the code. First, let’s use it to compute a polynomial, by calling it with c being a polynomial of degree 1.
z = Mandelbrot(4, Poly([0, 1])) # The above code works with Polys (defined in previous cell)
print(z)
0.0 + 1.0·x¹ + 1.0·x² + 2.0·x³ + 5.0·x⁴ + 6.0·x⁵ + 6.0·x⁶ + 4.0·x⁷ +
1.0·x⁸
z = Mandelbrot(4, -1.2) # The code also works with numeric input
print(z)
0.10507775999999969
z = Mandelbrot(21, 1.0j) # Will work with complex numbers also
print(z)
-1j
z = Mandelbrot(30, -1.2) # Since it is iterative, we can ask for high iteration numbers on numerical input
print(z)
# Don't try that with c = Poly([0,1]) though; the result would be a vector of length half a billion or so
0.17381269635430296
zbig = Mandelbrot(7, Poly([0, 1])) # n=8 is ghastly already; n=9 is twice as ghastly
print(zbig)
0.0 + 1.0·x¹ + 1.0·x² + 2.0·x³ + 5.0·x⁴ + 14.0·x⁵ + 42.0·x⁶ + 132.0·x⁷ +
365.0·x⁸ + 950.0·x⁹ + 2398.0·x¹⁰ + 5916.0·x¹¹ + 14290.0·x¹² +
33708.0·x¹³ + 77684.0·x¹⁴ + 175048.0·x¹⁵ + 385741.0·x¹⁶ + 831014.0·x¹⁷ +
1749654.0·x¹⁸ + 3598964.0·x¹⁹ + 7228014.0·x²⁰ + 14162220.0·x²¹ +
27049196.0·x²² + 50323496.0·x²³ + 91143114.0·x²⁴ + 160617860.0·x²⁵ +
275276716.0·x²⁶ + 458591432.0·x²⁷ + 742179284.0·x²⁸ + 1166067016.0·x²⁹ +
1777171560.0·x³⁰ + 2625062128.0·x³¹ + 3754272037.0·x³² +
5193067630.0·x³³ + 6939692682.0·x³⁴ + 8948546308.0·x³⁵ +
11120136162.0·x³⁶ + 13299362332.0·x³⁷ + 15286065700.0·x³⁸ +
16859410792.0·x³⁹ + 17813777994.0·x⁴⁰ + 17999433372.0·x⁴¹ +
17357937708.0·x⁴² + 15941684776.0·x⁴³ + 13910043524.0·x⁴⁴ +
11500901864.0·x⁴⁵ + 8984070856.0·x⁴⁶ + 6609143792.0·x⁴⁷ +
4562339774.0·x⁴⁸ + 2943492972.0·x⁴⁹ + 1766948340.0·x⁵⁰ + 981900168.0·x⁵¹ +
502196500.0·x⁵² + 234813592.0·x⁵³ + 99582920.0·x⁵⁴ + 37945904.0·x⁵⁵ +
12843980.0·x⁵⁶ + 3807704.0·x⁵⁷ + 971272.0·x⁵⁸ + 208336.0·x⁵⁹ +
36440.0·x⁶⁰ + 4976.0·x⁶¹ + 496.0·x⁶² + 32.0·x⁶³ + 1.0·x⁶⁴
# If you forget the ordering, you can use keyword arguments ("kwargs")
zforgot = Mandelbrot(c=Poly([0,1]), n=5)
print(zforgot)
0.0 + 1.0·x¹ + 1.0·x² + 2.0·x³ + 5.0·x⁴ + 14.0·x⁵ + 26.0·x⁶ + 44.0·x⁷ +
69.0·x⁸ + 94.0·x⁹ + 114.0·x¹⁰ + 116.0·x¹¹ + 94.0·x¹² + 60.0·x¹³ +
28.0·x¹⁴ + 8.0·x¹⁵ + 1.0·x¹⁶
One advantage of using Polynomials from NumPy is that they “know how to find their own roots”. Let’s test that out; the Mandelbrot polynomials turn out to be tough customers, though (which is why they are used as test problems for MPSolve, not at all coincidentally—we learned about them first from the MPSolve test suite).
N = 5
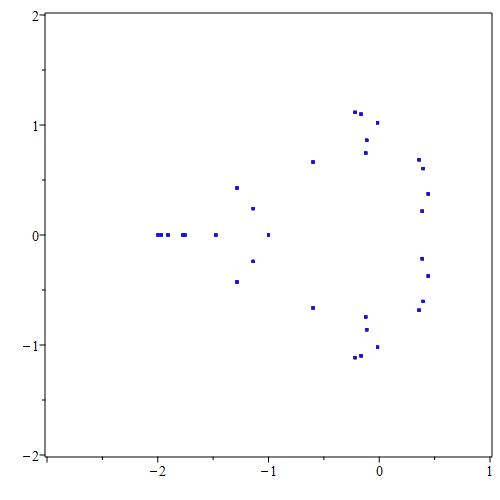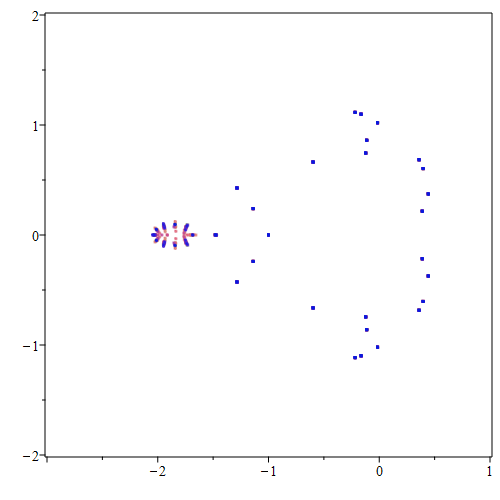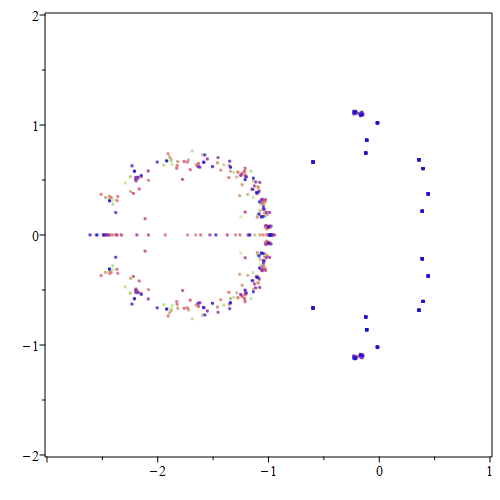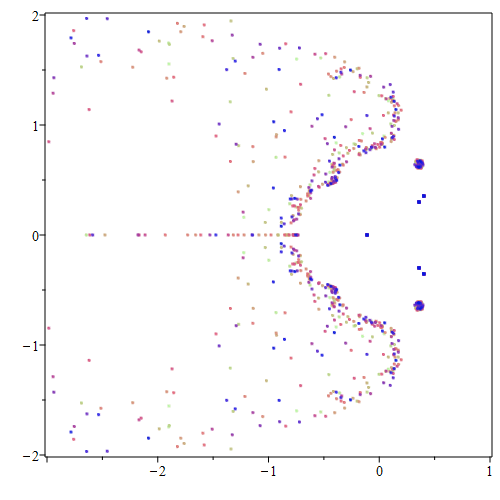
p = Mandelbrot(N, Poly([0,1]))
rts = p.roots()
# print(rts)
import matplotlib.pyplot as plt
x = [rt.real for rt in rts]
y = [rt.imag for rt in rts]
rootplot = plt.figure(figsize=(8,8))
plt.scatter(x, y, s=15, marker=".")
plt.xlim(-2.5,0.5)
plt.ylim(-1.5,1.5)
plt.show()
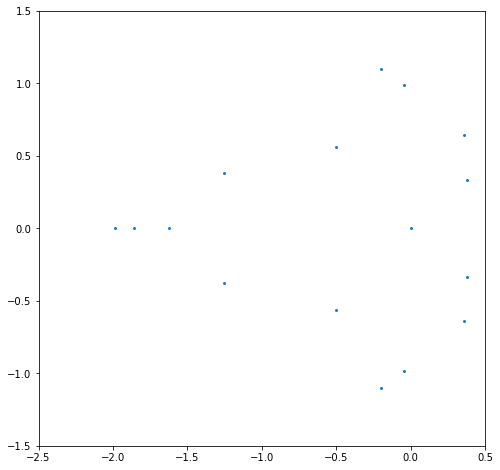
# Great. Are those roots correct?
residuals = [p(rt) for rt in rts]
# print(residuals) shows them all, and it's a confusing mess
absresiduals = [abs(r) for r in residuals]
print(max(absresiduals))
7.9566866626094e-11
That’s, that’s ok; it looks like we have in every case found the exact root of a polynomial different from \(z_5(c)\) by no more than \(3\cdot 10^{-11}\). Wait, what? Well, putting in a computed root back to the polynomial (assuming it evaluates correctly) gives us a residual, say \(r\). That is \(p(c^*) = r\), some (hopefully small) complex number. But then \(c^*\) is the exact root of the following polynomial: \(p(c) - r\).
Two questions: Did Python evaluate the polynomial well? That is, are the residuals accurate? And second, what happens to a root if we slightly change a polynomial? We’ve just wandered into numerical analysis territory. Let’s first compare the built-in evaluation of a polynomial by its coefficients to our iterative code.
r1 = rts[0]
residual1byPython = p(r1)
residual1byIteration = Mandelbrot(n=N, c=r1)
print("Using n = ", N, "\nFor the computed root ", r1, "The residual by Python is ", residual1byPython,
"\nwhile the residual by iteration is ", residual1byIteration)
Using n = 5
For the computed root (-1.985424253054647+0j) The residual by Python is (7.9566866626094e-11+0j)
while the residual by iteration is (4.705902334478651e-11+0j)
We see some minor difference in that computation. But it seems nothing to worry about. Perhaps we should try a larger N, just to be sure?
N = 6
p = Mandelbrot( N, Poly([0,1]))
rts = p.roots()
residuals = [p(rt) for rt in rts]
# print(residuals) shows them all, and it's a confusing mess
absresiduals = [abs(r) for r in residuals]
print(max(absresiduals))
r1 = rts[0]
residual1byPython = p(r1)
residual1byIteration = Mandelbrot(n=N, c=r1)
print("Using n = ", N, "and degree d = ", p.degree(), "\nFor the computed root ", r1, "The residual by Python is ", residual1byPython,
"\nwhile the residual by iteration is ", residual1byIteration)
x = [rt.real for rt in rts]
y = [rt.imag for rt in rts]
rootplot = plt.figure(figsize=(8,8))
plt.scatter(x, y, s=15, marker=".")
plt.xlim(-2.5,0.5)
plt.ylim(-1.5,1.5)
plt.show()
0.0006066958003114083
Using n = 6 and degree d = 32
For the computed root (-1.9963775684547609+0j) The residual by Python is (0.0006066958003114083+0j)
while the residual by iteration is (0.0006180627093101965+0j)
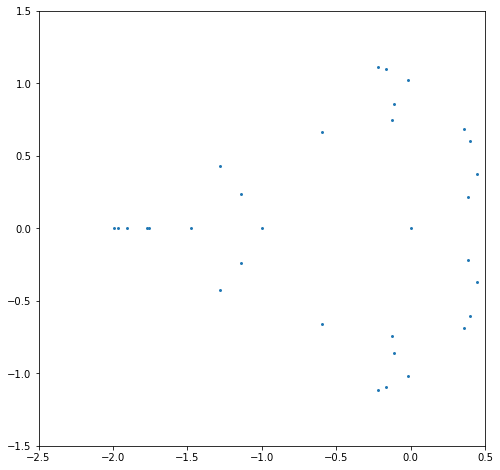
Ooh, that’s not very good. When we try n=7 (below) we will see it get much worse; n=8 and worse yet (ridiculously worse). Try it yourself, and see! The issue seems to either be Python’s polynomial rootfinder (we kind of thought it would be bad, but were hoping it was better than that), or its evaluation of the polynomial from its coefficients. Of course the two things are connected.
N = 7
p = Mandelbrot(N, Poly([0,1]))
rts = p.roots()
residuals = [p(rt) for rt in rts]
# print(residuals) shows them all, and it's a confusing mess
absresiduals = [abs(r) for r in residuals]
print(max(absresiduals))
r1 = rts[0]
residual1byPython = p(r1)
residual1byIteration = Mandelbrot(n=N, c=r1)
print("Using n = ", N, "and degree d = ", p.degree(), "\nFor the computed root ", r1, "The residual by Python is ", residual1byPython,
"\nwhile the residual by iteration is ", residual1byIteration)
x = [rt.real for rt in rts]
y = [rt.imag for rt in rts]
rootplot = plt.figure(figsize=(8,8))
plt.scatter(x, y, s=15, marker=".")
plt.xlim(-2.5,0.5)
plt.ylim(-1.5,1.5)
plt.show()
813032006381.8693
Using n = 7 and degree d = 64
For the computed root (-2.2462535595968096-0.09498061432630142j) The residual by Python is (483296675303.2549-653793061329.155j)
while the residual by iteration is (462256662183.5727-641275610267.817j)
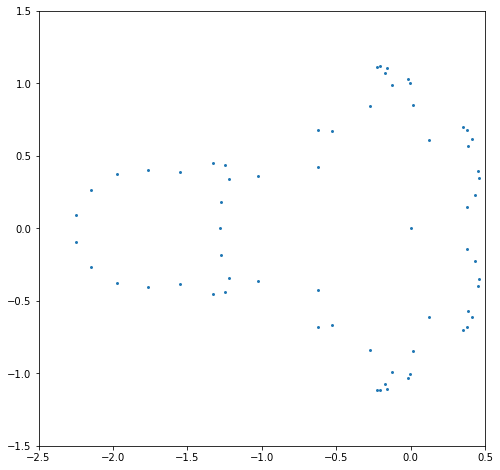
The fact that the roots near \(-2\) have exploded (which explains the fireworks GIF at the beginning of the online version of this unit) can be explained using what are known as pseudozeros.
Instead of pursuing that now, though, let us do something different. Namely, let us introduce an approximate formula for the largest magnitude root:
This formula was published in 2013 by one of us (RMC) and his then-student Piers W. Lawrence, and with the help of another of us (NJC). We (the present authors, including EYSC) discuss it a bit in our paper Some Facts and Conjectures on Mandelbrot Polynomials but for now let’s just use it.
import math
rho = lambda k: -2 + 3*math.pi**2*4**(-k)/2
print(rho(5) - -1.9854242530543296) # Was -1.9854242530543296 above
print(rho(6) - -1.9963773629263977) # Was -1.9963773629263977+0j above
print(4**6*Mandelbrot(n=6, c=rho(6))) # Like 4 times 4 (pattern observed experimentally)
print(4**7*Mandelbrot(n=7, c=rho(7))) # Like 4 times 5
print(4**8*Mandelbrot(8, rho(8))) # Like 4 times 6
print(4**9*Mandelbrot(9, rho(9))) # Like 4 times 7
print(4**13*Mandelbrot(13, rho(13))) # Like 4 times 11
-0.00011831862376210367
-8.279993125359653e-06
16.828183511695897
20.712561469499633
24.591600405416102
28.468529149366077
44.025735571980476
Now we see something interesting (to a numerical analyst). The largest root (computed by Python) is actually better than its residual indicates! We also see something interesting to an analyst, namely that there seems to be pattern in the residual. The experiments above predict that
and if this were true in general then this would be enough to deduce that there really is a root nearby: one Newton correction from here will help as we will see below (but this turns out to be tricky because the second derivatives are so large in this area; this fact interferes with the theory of Newton iteration, as you may eventually see in your numerical analysis class).
Now let us see a nifty way to compute derivatives of the iteration: just differentiate the statements in the loop, as follows! But we have to be careful to do it in the right order (this is quite weird).
def MandelbrotWithDerivative(n: int, c):
dz = 0*c
z = 0*c # try to inherit the type of c
for i in range(n):
dz = 2*z*dz + 1 # A bit iffy to add constants to Polynomials in Python, but maybe it works. Yes! It does!
z = z*z + c
return(z,dz)
print(MandelbrotWithDerivative(3, -1.2))
print(MandelbrotWithDerivative(3, Poly([0,1])))
(-1.1423999999999999, 0.32800000000000007)
(Polynomial([0., 1., 1., 2., 1.], domain=[-1., 1.], window=[-1., 1.]), Polynomial([1., 2., 6., 4.], domain=[-1., 1.], window=[-1., 1.]))
The output there is a bit hard to read, but it looks like it worked; the derivative of \(z_3 = c + c^2 + 2c^3 + c^4\) is indeed \(1 + 2c + 6c^2 + 4c^3\). We don’t really know what all that “domain” and “window” stuff is, but let’s just use the numerical part: if we plug in \(c=-1.2\) into \(1 + 2c + 6c^2 + 4c^3\) we should get \(0.328\). Let’s try it and see.
pd = Poly([1,2,6,4])
print(pd(-1.2))
0.3280000000000002
That looks good. On this machine at the time of writing, the final digits are different (2 vs 7 from before) but it’s convincing. That code computes both \(z(c)\) and \(z'(c)\), with the same loop. So we can now take a Newton step. Or two.
pdp = MandelbrotWithDerivative(6, rho(6))
improved = rho(6) - pdp[0]/pdp[1]
print(rho(6), pdp[0], pdp[1], improved, Mandelbrot(6,improved))
pdp2 = MandelbrotWithDerivative(6, improved)
better = improved - pdp2[0]/pdp2[1]
print(better, Mandelbrot(6,better))
-1.996385642919523 0.004108443240160131 -432.51765820326005 -1.9963761440166177 2.7235905697420293e-06
-1.9963761377111966 1.2387868508767497e-12
Good! Now we can (maybe) check Python’s rootfinder for larger \(N\). Let’s try \(N=8\).
N = 8
z = Mandelbrot( N, Poly([0,1]))
print(z.degree())
rts = z.roots()
print(rts[0]) # Hopelessly wrong (can't be smaller than -2)
rho8 = rho(8)
print(z(rho8)) # Disaster has struck the polynomial evaluation
print(Mandelbrot(n=N, c=rho8)) # The iteration is better; *much* better
128
(-3.5776231050281337+0j)
1.2508702354809364e+33
0.0003752380432955338
We see that the built-in Python rootfinder has failed hopelessly, already at \(N=8\) (when there are only \(128\) roots to compute). There is a technical issue here: this polynomial is what is known as ill-conditioned. That means that it is sensitive to changes in its input. We could pursue that, with the notion of pseudozeros (and that’s what leads to the fireworks GIF that we opened this section with online), but for the moment we will try another tack: instead of working with Mandelbrot polynomials, we will work with Mandelbrot matrices, which turn out to be much better behaved.
Mandelbrot Activity 7
Prove by induction that the code MandelbrotWithDerivative computes the correct derivative of every Mandelbrot polynomial. Rather, that it would compute the correct derivative if the underlying arithmetic were exact. You might need what is known as a loop invariant: something that is true before the loop starts, and is true at the start of every iteration, and at the end of every iteration (though not necessarily true after each intermediate step of the iteration). But this loop is simple enough that a direct induction also works.
[Our proof]
Mandelbrot Activity 8
Are the zeros of the derivatives of the Mandelbrot polynomials in the Mandelbrot set? [We think so, but we don’t know.]
Eigenvalues and roots of polynomials#
In the previous unit, on Bohemian matrices, we introduced matrices (via determinants) and eigenvalues of matrices. In this unit, we’re going to use them without defining them further. This is kind of backwards if you haven’t had a course in linear algebra, but we also saw two-by-two matrices at least back in the Fibonacci unit, and many high schools do cover matrices at least a little bit. Eigenvalues, not so much. But then, eigenvalues aren’t covered enough in many first courses in linear algebra, either, so the practice here is justified, in our minds.
Eigenvalues of matrices are related to roots of polynomials in the following two ways: first, if we are given a monic polynomial, say \(x^3 -2 x^2 - 5x + 9\), then the three-by-three matrix below (three by three because the polynomial has degree \(3\))
has as its eigenvalues the exact roots of the polynomial. Notice that the negatives of the polynomial coefficients appear in the final column, and that there is a diagonal of 1s appearing below the main diagonal of the matrix. This construction is perfectly general: take any monic polynomial, negate its coefficients (except the leading coefficient, which is 1), list them in increasing degree as you go down the final column, and throw 1s along the subdiagonal, then you have a matrix whose eigenvalues are the roots of the original polynomial. This is called a companion matrix for the polynomial (there are many: this is the Frobenius companion matrix).
Since Python (and every scientific computing language) has a routine to compute eigenvalues, this gives us a perfectly straightforward way to find the roots of a polynomial.
from scipy.linalg import eigvals, tri
A = np.zeros([3,3])
A[0,2] = -9
A[1,0] = 1
A[1,2] = 5
A[2,1] = 1
A[2,2] = 2
e = eigvals(A)
print(A, e)
[[ 0. 0. -9.]
[ 1. 0. 5.]
[ 0. 1. 2.]] [-2.18194334+0.j 1.59357935+0.j 2.58836399+0.j]
p = Poly( [9,-5,-2,1])
print(p, p.roots())
residuals = [p(t) for t in e]
print(residuals)
9.0 - 5.0·x¹ - 2.0·x² + 1.0·x³ [-2.18194334 1.59357935 2.58836399]
[(-4.263256414560601e-14+0j), (-1.7763568394002505e-15+0j), (-3.552713678800501e-15+0j)]
Voilà. The same numbers appear (possibly in a different order). This is in fact how numpy’s roots command works, and how the Polynomial package allows its polynomials to find their roots. Notice that the values of the polynomial at the computed eigenvalues are all nearly zero, and the difference (when its not actually zero) is small enough to be considered the effects of rounding error.
But wait, that’s backwards!#
The second way of connecting matrices and polynomials, though, is one we have seen already: given a matrix, we define its eigenvalues as the roots of its “characteristic polynomial”. This is “reducing the problem to a previously solved one”, if you know how to find roots of polynomials. Turns out, that’s actually harder, computationally speaking! But for the record, here is where we got that polynomial in the first place.
which has characteristic polynomial det\((\lambda\mathbf{I}-\mathbf{B}) = \lambda^{3}-2 \lambda^{2}-5 \lambda +9 \). Apart from the variable name, this is the same polynomial as above. Therefore both \(\mathbf{B}\) and \(\mathbf{A}\) have the same eigenvalues.
B = np.array([[2,-1,2],[-1,0,1],[1,2,0]])
print(B, eigvals(B))
[[ 2 -1 2]
[-1 0 1]
[ 1 2 0]] [-2.18194334+0.j 2.58836399+0.j 1.59357935+0.j]
Remark 1
It may seem silly, and wasteful, to solve polynomials by finding eigenvalues of matrices. Against that, we actually have software for eigenvalue problems that is really good in the sense that it is robust, accurate, and efficient. So we are “reducing the problem to a previously solved problem” which is like recycling, and so is not wasteful in that sense. However, at some point the wastefulness (we store \(d^2\) numbers, or sometimes even more, to attack a polynomial of degree \(d\)) will catch up to us. But it turns out that this “wasteful” approach gets us farther than trying to solve the Mandelbrot polynomials directly does.
It does turn out to be wasteful to start with a matrix, compute a characteristic polynomial, and then construct another matrix. You might just as well have computed the eigenvalues of the original matrix. Indeed, that’s almost always much better from the point of view of numerical stability. But that is a topic for your numerical analysis class.
Mandelbrot Activity 9
This is a more theoretical activity, and helps to explain why polynomials are sometimes hard to deal with directly in numerical computation. This particular discussion is not in many textbooks, but is in some. “A good numerical method gives you the exact solution to a nearby problem”. This is an informal definition of numerical stability. An algorithm is “numerically stable” if it gives you the exact solution, not to the problem you were trying to solve (say the polynomial \(z(c) = 0\)) but instead to a nearby problem, say \(z(c) - 10^{-16}i = 0\). Some problems, however, are sensitive to changes (in the vernacular of numerical analysis, ill-conditioned). Consider the polynomial \(z(c) = \sum_{k=0}^d a_k c^k\) and a perturbed (changed) polynomial \(z(c) + \Delta(c) = \sum_{k=0}^d a_k(1+s_k) c^k\) where the coefficients \(a_k\) have all been changed by small relative amounts \(s_k\). Suppose further that all \(|s_k| \le t\), some tiny number. By using the triangle inequality, show that \( | \Delta(c) | \le K(c) t \) where \( K(c) = \sum_{k=0}^d |a_k| |c|^k \) This number \(K(c)\) serves as a kind of condition number for the polynomial: the larger it is, the more sensitive the polynomial is. Plot the condition numbers (on a log scale!) of the Mandelbrot polynomials \(z_6(c)\) and \(z_7(c)\) on \(-2 \le c \le 0\). [Our thoughts]
Mandelbrot Activity 10
Pseudozeros. The zeros of \(z(c) - 10^{-k}\exp(i\theta)\) for \(k=6\), say, represent a curve in \(c\) space (let \(\theta\) vary from \(-\pi\) to \(\pi\) so the tiny perturbation \(10^{-6}\exp(i\theta)\) turns a full circle in the complex plane). As \(k\) is taken larger, one expects these curves to surround the zeros of \(z(c)\) itself. Graph some pseudozeros of a Mandelbrot polynomial.
[Our code]
Mandelbrot matrices#
Let \(\mathbf{M}_1 = [c]\) be the \(1\)-by-\(1\) matrix whose determinant is \(z_1(c)\). Now define
Here the \(\mathbf{e}_j\)’s are the unit elementary vectors of dimension \(d_k=2^{k-1}\); all they do together here is put a \(1\) in the top right corner of the relevant blocks.
Just to explain that a bit more: if the dimension is 5, say, then \(\mathbf{e}_1^T = [1,0,0,0,0]\) and \(\mathbf{e}_5^T = [0,0,0,0,1]\). The superscript T means “transpose” and we can use it (as in this paragraph) just to save space and write the column vectors on one line, or we can use it as in the formula to indicate what we really mean. Elementary vectors are all zero except for one 1, and they are used here just to keep the notation neat. They do have many other uses, so we don’t mind introducing a notation for such a simple-looking thing. The product \(\mathbf{e}_1^T\mathbf{e}_5\) is a \(5\) by \(5\) matrix that is all zero except for a \(1\) in the upper right hand corner.
The next two Mandelbrot matrices are then, by this recurrence relation,
and
where we have bold-faced the two new entries that connect the two copies of \(\mathbf{M}_2\) that lie in the upper left corner and bottom right corner.
We can write this matrix as \(\mathbf{A} + c\mathbf{B}\) where
and
Finding values of \(c\) which make the determinant of \(\mathbf{A} + c \mathbf{B}\) equal to zero is an example of what is called a generalized eigenvalue problem, and SciPy’s linalg routine eigvals is set up do do this already, except that it solves problems of the form \(\det( \mathbf{A} - \lambda \mathbf{B} ) = 0\) so we will have to change the sign of our matrix \(\mathbf{B}\).
The matrix \(\mathbf{A_k}\) is analogous at every dimension \(k\): it is zero except for the subdiagonal which is all \(1\)s. The matrix \(\mathbf{B}_k\) is very simply constructed from two copies of the matrix \(\mathbf{B}_{k-1}\) (if \(k>1\)), with an additional \(-1\) tucked into the upper right corner. We might as well build \(-\mathbf{B}_k\) instead of building \(\mathbf{B}_k\) while we are at it. We will do this recursively. See the code below.
def getMinusBmatrix(n: int):
d = 2**(n-1)
if n==1:
minusB = -np.ones([1,1]) # Return a 1 by 1 matrix of ones
return( minusB )
else:
zeroBlock = np.zeros([d//2,d//2]) # The double slash enforces integer division
smallerB = getMinusBmatrix(n-1) # This is a recursive program: it calls itself.
minusB = np.bmat('smallerB, zeroBlock; zeroBlock, smallerB')
minusB[0,-1] = 1 # Glue the two blocks together with a 1 in the upper right corner
return(minusB)
def getAmatrix(n: int):
d = 2**(n-1)
A = np.zeros([d,d])
for i in range(1,d):
A[i,i-1] = 1 # Subdiagonal entries are all 1, everything else is 0
return A
N = 2
A = getAmatrix(N)
B = getMinusBmatrix(N)
print(N, A , "\n", B)
2 [[0. 0.]
[1. 0.]]
[[-1. 1.]
[ 0. -1.]]
N = 3
A = getAmatrix(N)
B = getMinusBmatrix(N)
print(N, A, "\n", B)
3 [[0. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
[[-1. 1. 0. 1.]
[ 0. -1. 0. 0.]
[ 0. 0. -1. 1.]
[ 0. 0. 0. -1.]]
N = 4
A = getAmatrix(N)
B = getMinusBmatrix(N)
print(N, A, "\n", B)
4 [[0. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0.]]
[[-1. 1. 0. 1. 0. 0. 0. 1.]
[ 0. -1. 0. 0. 0. 0. 0. 0.]
[ 0. 0. -1. 1. 0. 0. 0. 0.]
[ 0. 0. 0. -1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. -1. 1. 0. 1.]
[ 0. 0. 0. 0. 0. -1. 0. 0.]
[ 0. 0. 0. 0. 0. 0. -1. 1.]
[ 0. 0. 0. 0. 0. 0. 0. -1.]]
N = 8
A = getAmatrix(N)
B = getMinusBmatrix(N)
# Now compute the generalized eigenvalues
E = eigvals(A, B)
x = [e.real for e in E]
y = [e.imag for e in E]
residuals = [Mandelbrot(N,e) for e in E]
absresiduals = [abs(r) for r in residuals]
print(max(absresiduals))
4.134470543704083e-11
rootplot = plt.figure(figsize=(8,8))
plt.scatter(x, y, s=15, marker=".")
plt.xlim(-2.5,0.5)
plt.ylim(-1.5,1.5)
plt.show()
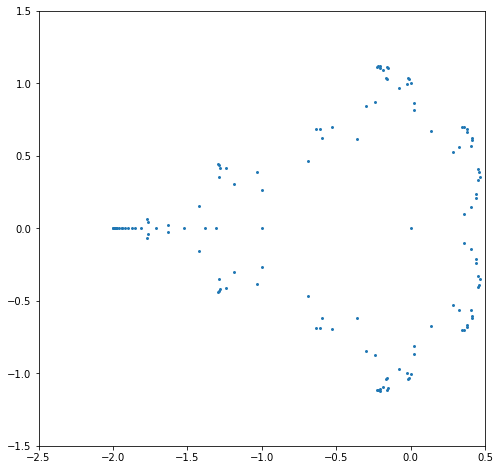
This shows that (at least for \(N=8\)) solving the (generalized) eigenvalue problem is much more accurate than trying to solve the explicit Mandelbrot polynomial at the same dimension.
Now it turns out that the matrix method will also (eventually) run into trouble, at about \(N=17\) (when RMC’s computer tries to store all the zeros in the \(d\) by \(d\) matrix, and runs out of memory); the dimension of the matrix for \(N=14\) is already \(16384\) by \(16384\), using about sixteen thousand times too much memory, and so this isn’t that surprising.
Here are some results of running this code on a 2019 Microsoft Surface Pro (1.3GHz, 4 cores; not that the 4 cores are specially used by Python). We report the Mandelbrot index, the dimension, the time taken in seconds, and the maximum absolute value of the residual. We see that in all the cases we get accurate roots, but we also see that as the dimension doubles the cost increases by more than a factor of \(2^3=8\), consistently; we do not know why. We estimated that running this for \(N=14\) would take about \(3\) hours (it took \(2\) hours and \(22\) minutes), and would return all roots to about single precision accuracy, which it did (we are working in double precision, of course). We could use a supposedly faster language (Julia, for instance: except that, ironically, Python seems to be faster for generalized eigenvalues) to speed the computation up, but the condition number of these eigenvalues also seems to be growing; this means the accuracy will diminish. Another approach seems needed: see MPSolve, and see Eunice Chan’s Master’s thesis. Also, generalized eigenvalue code is (quite a bit!) slower than code for the simple eigenvalue problem \(\mathbf{A}\mathbf{x} = \lambda \mathbf{x}\) and we could convert our generalized eigenvalue problem to a simple one by postmultiplying by \(\mathbf{B}^{-1}\) (we can even do that analytically, and this works very well: see the activities) but for now we will step away from the keyboard, happy with accurately computing the roots of the degree \(8192\) Mandelbrot polynomial by means of a generalized eigenvalue problem.
n |
d |
time(s) |
slowdown |
max residual |
|---|---|---|---|---|
9 |
256 |
0.06 |
\(2.8\cdot 10^{-11}\) |
|
10 |
512 |
0.6 |
10. |
\(1.8\cdot 10^{-10}\) |
11 |
1024 |
6 |
10. |
\(1.6\cdot 10^{-9}\) |
12 |
2048 |
78 |
13. |
\(3.5\cdot 10^{-9}\) |
13 |
4096 |
850 |
11. |
\(2.0\cdot 10^{-8}\) |
14 |
8192 |
8512 |
10. |
\(4.0\cdot 10^{-7}\) |
Remark 2
If we are more careful with memory and use what are known as sparse matrices, then we can go a lot farther. Using sparse matrices, and special algorithms for finding eigenvalues of sparse matrices, Piers Lawrence was able to take this approach up to about a half a million eigenvalues (\(n=19\)); it was a bit awkward to make sure that we got all the eigenvalues once and only once, but it worked. Eunice Chan got up over two million eigenvalues with a different method (homotopy continuation), but the champion is still MPSolve; Dario Bini and Leonard Robol used their software to compute over four million roots of Mandelbrot polynomials.
import time
start = time.time()
N=9
A = getAmatrix(N)
B = getMinusBmatrix(N)
# print( A, "\n", B )
built = time.time()
E = eigvals(A, B)
end = time.time()
x = [e.real for e in E]
y = [e.imag for e in E]
residuals = [Mandelbrot(N,e) for e in E]
absresiduals = [abs(r) for r in residuals]
print(max(absresiduals))
print("Time taken was ", end-built, "seconds to find d=", 2**(N-1),
"\ngeneralized eigenvalues of matrices that took ", built-start, "seconds to build")
1.0914269488182526e-10
Time taken was 0.13111090660095215 seconds to find d= 256
generalized eigenvalues of matrices that took 0.0018339157104492188 seconds to build
rootplot = plt.figure(figsize=(8,8))
plt.scatter(x, y, s=0.5, marker=".")
plt.xlim(-2.5,0.5)
plt.ylim(-1.5,1.5)
plt.show()
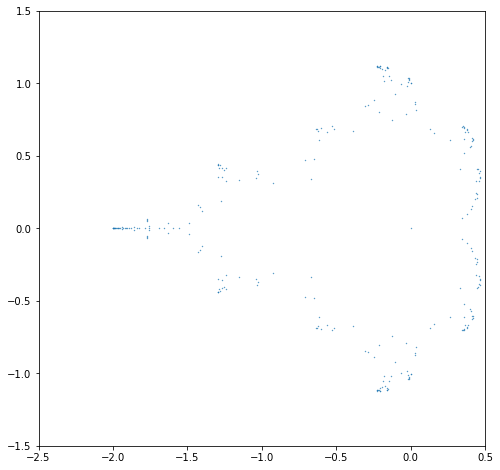
The following is the resulting image from the case \(N=14\):

Looking back at the programming constructs used in this unit#
We introduced more linear algebra routines. We found out how to compute roots of polynomials (by computing eigenvalues of companion matrices, using the eigenvalue routine as a “black box”). We used the // integer division operation for the first time.
We introduced “hints” for the types of arguments in a procedure. This is more important in other languages than in Python (indeed, it is critical for many).
We showed a programmatic method for inheriting types (not actually necessary in the example we used, because adding scalars to Polynomials produces a Polynomial anyway). And in the only case where it would matter, it didn’t work because Python was lazy about 0 times a Polynomial (it should return a Polynomial with zero coefficients, but just returns a scalar 0).
We showed that one can differentiate a program or take the derivative of a program (indeed this can be done by computers as well, in which case it is called “automatic differentiation” or “program differentiation”). Doing this efficiently is sometimes an issue, but given how tedious differentiation can be, we will take all the help we can get.
More Mandelbrot Activities#
11. Write \(\mathbf{C} = \mathbf{A}\mathbf{B}^{-1}\) and show that the generalized eigenvalues of \(\mathbf{A}-\lambda\mathbf{B}\) are the simple eigenvalues of \(\mathbf{C} - \lambda\mathbf{I}\). Find \(\mathbf{C}\) for the Mandelbrot matrices above, and code it up and compare the times to compute simple eigenvalues versus generalized eigenvalues. How high a degree can you get to? We stopped at \(N=16\), where the computation took about an hour and a half, and the residual was about \(4.0e-5\). The current record is held by MPSolve with \(k=23\), so over \(4\) million roots (using multiple precision); we don’t think eigenvalue methods can get that high, but we think homotopy methods can (also called “continuation methods” as they were in the Rootfinding unit, as a “really good way to get initial estimates”), although they haven’t yet. [Our thoughts]
12. Eigenvalues of perturbed matrices are called pseudospectra (the set of eigenvalues themselves is called the spectrum). \(\Lambda_\varepsilon(\mathbf{A}) := \{z : \exists \mathbf{E} \backepsilon \mathrm{det}(z\mathbf{I} - (\mathbf{A}+\mathbf{E})) = 0 \& \|\mathbf{E}\| \le \varepsilon\}\). That definition means, in words, that the pseudospectrum at size \(\varepsilon\) is the set of complex numbers \(z\) that are the exact eigenvalues of matrices perturbed by another matrix \(\mathbf{E}\) which is at most \(\varepsilon\) in norm. Check out the Pseudospectra gateway and then do some pseudospectral experiments with Mandelbrot matrices. [Our thoughts]
13. Other families of polynomials like the Mandelbrot polynomials can be defined: Fibonacci–Mandelbrot polynomials defined by \(q_{n+1}(z) = z q_n(z) q_{n-1}(z) + 1\) and \(q_0(z)=0\) and \(q_1(z) = 1\), for instance; or Fibonacci–Narayana polynomials. Define your own polynomials by recurrence relation, and find your own matrices whose eigenvalues are their roots, and draw their eigenvalues. We have only done a few of these, and there are infinitely many to choose from. It’s possible your results will be completely new (and therefore publishable). [Our thoughts]
14. The paper Some Facts and Conjectures on Mandelbrot Polynomials contains a formula for the Mandelbrot Generating Function MGF(k,c), which analytically solves the Mandelbrot iteration \(z_{n+1} = z_n^2 + c\), at least for \(c\) outside the Mandelbrot set. This means that we could (say) take half an iteration—and find \(z_{1/2}(c)\) or \(z_{3/2}(c)\). As with Stand-Up Math’s Video on Complex Fibonacci Numbers these are likely to be complex numbers. So far as we know, no-one (not even us) has computed these. Do so, for (say) \(c=1\) or \(c=2\). Plot the results. This, also, might be publishable (again, Maple Transactions might be a good place). [Our thoughts]
15. A companion matrix for a polynomial (say \(P(\lambda)\)) is simply a matrix \(C\) whose eigenvalues are the roots of \(P(\lambda)\). Every matrix has a characteristic polynomial whose roots are its eigenvalues; what’s interesting is that this can be run the other way (it’s a bit more complicated because “Frobenius companion matrices” as in the link above have special properties). But companion matrices are not unique: any matrix similar to a companion matrix \(\mathbf{S}\mathbf{C}\mathbf{S}^{-1}\) is also a companion matrix for that same \(P(\lambda)\). Suppose that you have a polynomial with integer coefficients. Then the Frobenius companion matrix has (those same) integers as entries, together with ones and zeros. Therefore, out of all integer companion matrices for \(P(\lambda)\), there must be one with minimal height: the height of the matrix is the size of the largest absolute value of any entry in the matrix. Mandelbrot matrices as defined above have height \(1\), which is the smallest possible for integer companions, and are therefore “minimal height”. Note that the size of the coefficients of the polynomial are exponential in the degree! So the height of the Frobenius companion matrix of Mandelbrot polynomials is likewise exponential. Not much is known about minimal height companion matrices (see also our first paper); we do not have an algorithm for finding one for a given integer polynomial, for instance. We believe that minimal height companion matrices are generally better-conditioned as far as their eigenvalues, but we have no proof. Find a minimal height companion matrix for (say) \(\lambda^3 + 5\lambda^2 + 3\lambda + 1\). Find a general algorithm for computing minimal height companions. Prove that they’re useful. If you succeed at this problem, you should certainly publish your results; a good venue might be the Electronic Journal of Linear Algebra. [Our thoughts]
16. Take some time and write down some of your own questions about this material. As you can see, there is lots left to discover, here. [Our thoughts]